SOM样本聚类 |
  
|
SOM样本聚类 |
|
地球化学 > SOM样本聚类
SOM样本聚类
在SOM训练中,每个样本都会在整个神经网络上产生某种形式的响应,其中响应最为强烈的神经元被称为本样本的“最佳匹配神经元”。EnviFusion支持对散点数据、网格数据、附加数据、表格数据等进行SOM样本聚类,并找出每个样本的最佳匹配神经元。由于神经网络需要尽可能多的样本进行训练,所以系统将首先遍历所有时间步,并将所有样本数据收集在一起,然后进行训练。
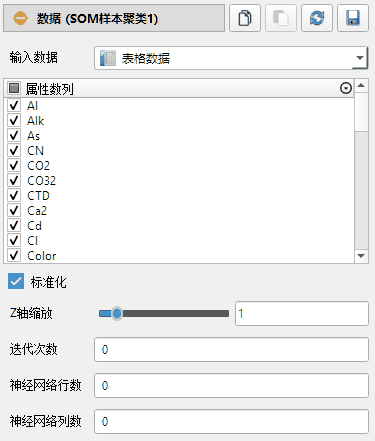
输入数据:请指定输入数据类型。包括散点数据、网格数据、附加数据、表格数据等。
属性数列:请选择参与计算的属性数列。
标准化:若选中,系统将输出标准化后的神经网络响应值;否则系统将输出原始响应值。
Z轴缩放:请选择聚类散点在Z轴上的缩放系数。默认为1,代表神经元内部将生成球形随机散点。若设为0,则在神经元内生成平面二维散点。最大值为10。
迭代次数:请指定神经网络训练的迭代次数,如不设置或设置为0,系统将默认使用20步。
神经网络行数:请指定神经网络的行数,如不指定,系统将自动计算。
神经网络列数:请指定神经网络的列数,如不指定,系统将自动计算。
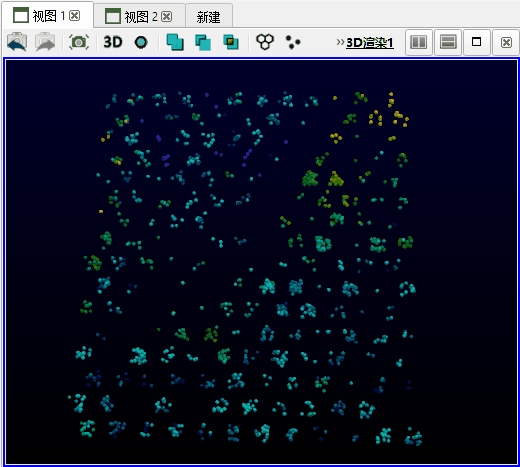
如上图所示,样本聚类后,输出图层的附加数据中将包含所有样本在神经网络中的坐标位置(efSOMX, efSOMY, efSOMZ),使用这些坐标生成散点可以直观观察每个样本在神经网络上所映射的位置。另外,输出图层的网格数据中将包含每个神经元网格对每个维度的响应值,根据这些响应模式的形态,用户可以分析各维度之间的关联。