时间序列补齐(LSTM) |
  
|
时间序列补齐(LSTM) |
|
数据补齐 >时间序列补齐(LSTMM)
时间序列补齐(LSTM)
在地下水监测领域,时间序列数据是必不可少的基础数据。传统的时序数据补齐通常以插值为基础,其中最为简单的插值方法为临点法,即以时间向前最靠近的或向后最靠近的有效数据作为该时间点的数据值;工程上运用较多的插值方法为样条插值,该方法需要插值所在位置前后两个或三个连续数据点,通过二次及三次多项式的拟合完成拟真。多项式插值的插值信息,根据多项式次数,仅来自临近的几个数据点,对于长时间序列的大范围补齐,有天生的缺陷。特别是面对周期数据时,无法捕捉周期涨落规律。本工具中使用的长短期记忆(LSTM)是一种人工循环神经网络(RNN)架构,用于深度学习领域。与标准的前馈神经网络不同,LSTM 具有反馈连接。它不仅可以处理单个数据点(例如图像),还可以处理整个数据序列(例如语音或视频)。
LSTM的全称是长短期记忆网络(Long-Short Term Memory),是具有长期记忆能力的一种时间递归神经网络 (Recurrent Neural Network),其网络结构含有一个或多个具有遗忘和记忆功能的单元。由于独特的设计结构,LSTM 适合于处理和预测时间序列中间隔和延迟非常长的重要事件。该论文首次发表于 1997 年。由德国慕尼黑工业大学的计算机科学家 Sepp Hochreiter 与 Jürgen Schmidhuber共同完成。LSTM的初次提出旨在解决RNN存在的梯度消失问题。朴素RNN神经网络的梯度消失问题,能够通过引入LSTM单元,通过记忆单元的梯度保留特性加以解决。
属性补齐工具在填补缺失数据时也同样使用了SOM工具,但其中参加训练的是属性数据本身;而在本工具中,参与训练的是时间序列数据的时序差分值,所以预测是基于断点位置的属性值和空缺位置的差分值共同确定的,既照顾了数据序列的连续性,又综合考虑了时序变化特征。LSTM模型是监督训练模型,预测结果较为激进,适用于缺失时间较长和水位波动周期性较强的场景。
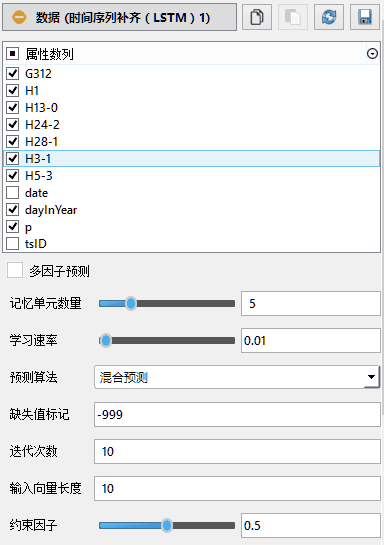
属性数列:请选择参与LSTM训练的属性数列。
多因子预测:选中此项后,系统将首先尝试使用选中的完整数列作为训练数据对缺失数列进行补齐;若用户选中的完整数列不足两列时,系统将重新使用单因子时间序列进行补齐。不选中此项时,系统将直接使用单因子时间序列进行训练补齐。
记忆单元数量:请指定LSTM神经网络记忆单元的数量。
学习速率:请输入预测算法的学习速率,默认为0.01。
预测算法:请指定时间序列的预测算法。正序预测意味着时间序列将从前至后依次进行训练;逆序预测意味着时间序列将从后向前依次训练;系统默认的混合预测则将使用二者的平均值。
缺失值标记:请输入数据集中代表缺失值(NaN)的整型数字,默认为-999。在准备原始数据时,请将缺失的数据统一替换为此数值。
迭代次数:请指定神经网络训练的迭代次数,默认为10步。
输入向量长度:请指定时间序列预测时使用的输入向量长度,此长度一般应覆盖输入信号的一个周期。多因子时间序列预测场景中,系统将忽略本因子。
约束因子:时间序列预测倾向于给出极端预测值,请在此处指定系统默认的约束因子,当补齐部分数据的振幅与总数据系列振幅的比例大于此值时,系统将禁止。默认为0.5。
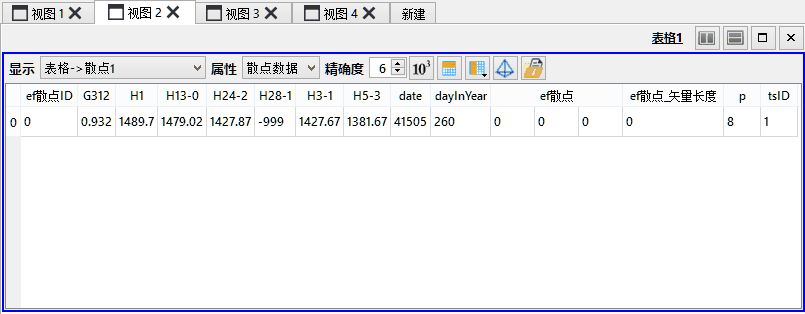
如上图所示,输入图层的散点数据中包含510个时间步,每一时间步中存在若干监测井的水位信息。运行本工具时,系统将首先收集全部时间段中的所有数据,并统一进行训练。
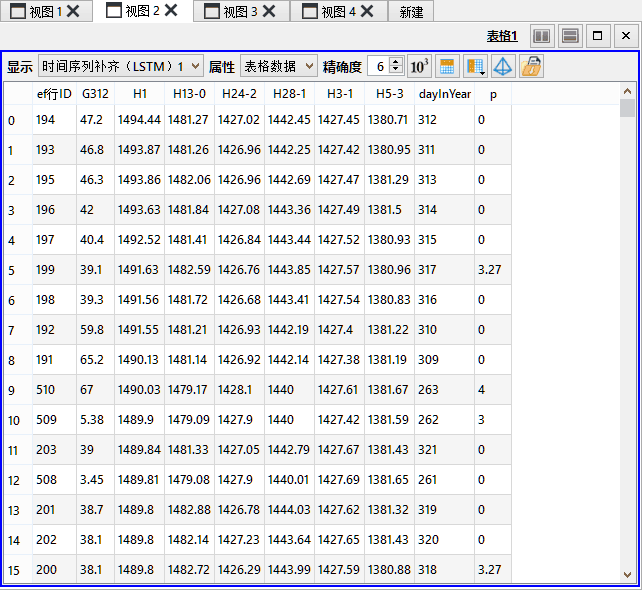
使用本工具后,输出图层的表格数据中将出现补齐之后的所有数据,注意原始数据中代表缺失数据的-999已经全部被替换成为SOM神经网络预测后的数值。