K Means聚类 |
  
|
K Means聚类 |
|
地球化学 > K Means聚类
K Means聚类
使用K Means算法对属性数列进行聚类。K Means是一类无监督学习算法,由于简洁和高效使其成为最广泛使用的聚类算法。在K Means中,由用户指定聚类数量K,由系统迭代将矩阵中的向量(行)分配到这K个聚类中,并保证误差平方和局部最小。EnviFusion支持对散点数据、网格数据、附加数据、表格数据等进行K Means聚类。
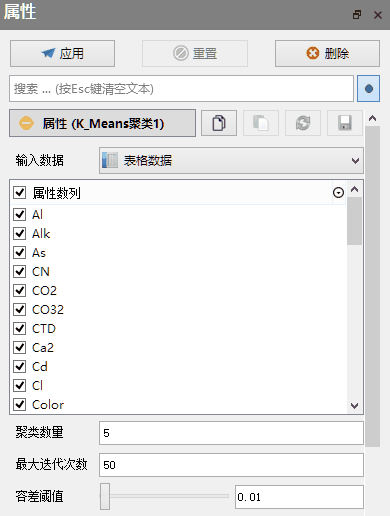
输入数据:请指定输入数据类型。包括散点数据、网格数据、附加数据、表格数据等。
属性数列:请选择参与计算的属性数列。
聚类数量:请指定聚类数量(K值)。
最大迭代次数:请指定K Means算法的最大迭代次数。
容差阈值:请指定用来判定收敛的容差阈值。
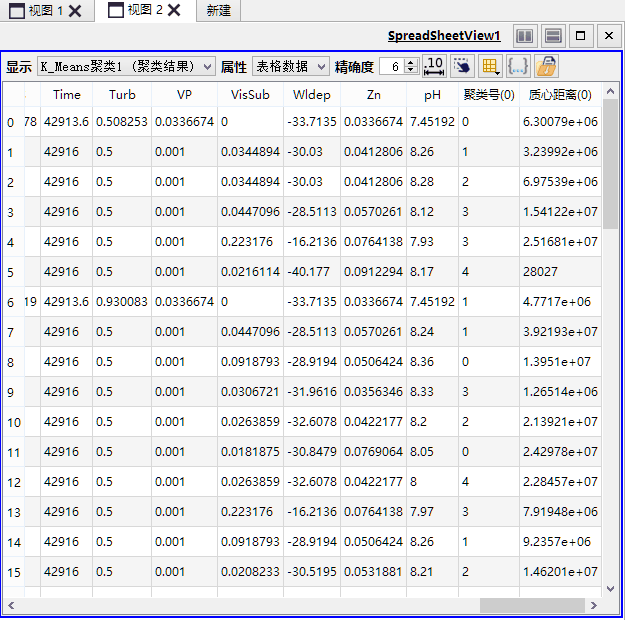
如上图所示,聚类后将在结果图层数据中生成两列新字段,一为从0开始计数的聚类号,用于后期分类渲染;二为本向量与本类质心之间的距离。