中文分词 |
  
|
中文分词 |
|
文本分析 >中文分词
中文分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。ENVIFUSION支持对表格数据进行中文分词操作,生成关键词矩阵。
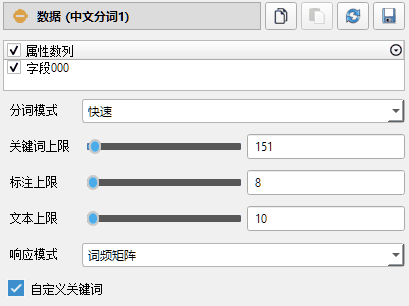
属性数列:请选择参与分词的表格数列。
分词模式:请选择分词模式。快速模式使用了FMM算法,适合速度要求场合。精确模式试用了MMSEG四种过滤算法,具有较高的歧义去除能力。检索模式仅返回词库中已有词条,适合特定场景应用。
关键词上限:本工具将为文本生成关键词矩阵,请指定关键词最大数量。出现频率最高的关键词将被保留在矩阵中。
标注上限:本工具将为每行文本生成文字标注,用来记录本行中出现的高频关键词,请在此处指定标注中包含关键词的最大数量,默认为5。
文本上限:本工具将为过长的原始文本做换行处理,以便于后期显示。请输入每行文本所包含的最大词数量。每行文本默认包含10个关键词。
响应模式:请选择文本关键词矩阵的响应模式。零一矩阵:本行语料数据中出现某关键词响应值为1,否则响应为0;词频矩阵:出现某关键词时响应值为本关键词在总语料中的词频,否则响应为0;TF-IDF矩阵:词频-逆文本加权后的关键词矩阵,是文本挖掘中经常使用的加权算法。
TF-IDF筛选阈值:当响应模式为TF-IDF时,需指定此参数。TF-IDF参数可以反映关键词对本条文本数据的重要程度,从而允许用户对分词结果进行筛选。请在此处设置TF-IDF筛选阈值,系统将忽略低于此阈值的关键词。默认为0,即不对关键词做任何筛选。
自定义关键词:系统默认使用关键词词频排序来确定关键词。若选中此项,系统将优先使用用户自行定义的关键词生成热词矩阵,并在附加数据中为每个关键词生成一列0/1数列;1代表本关键词出现在用户自定义词库中,0代表未出现。自定义词库位于lex-custom-words.lex配置文件中,用户可自行修订。
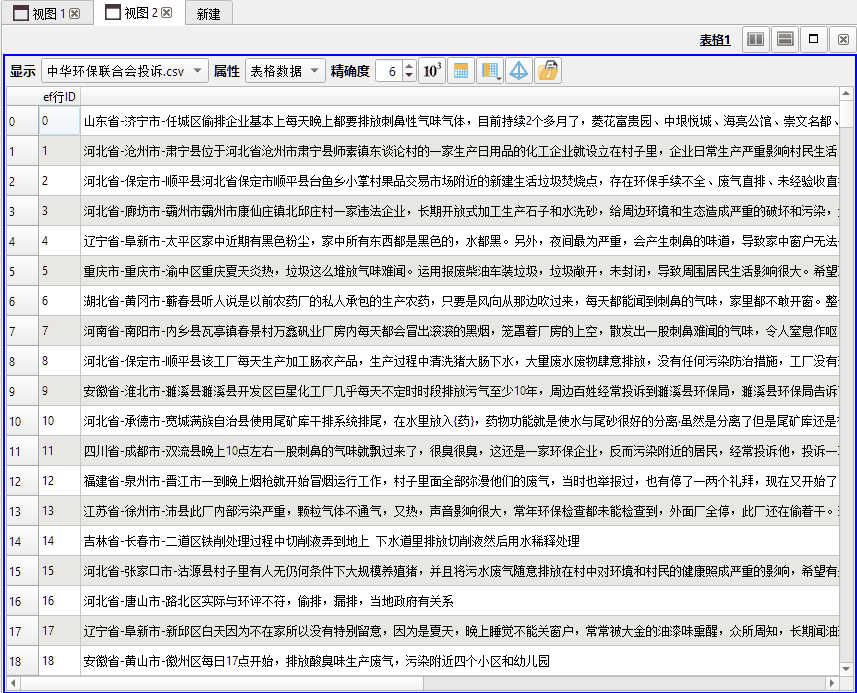
上图所示为输入图层中,未经分词处理的原始表格数据。
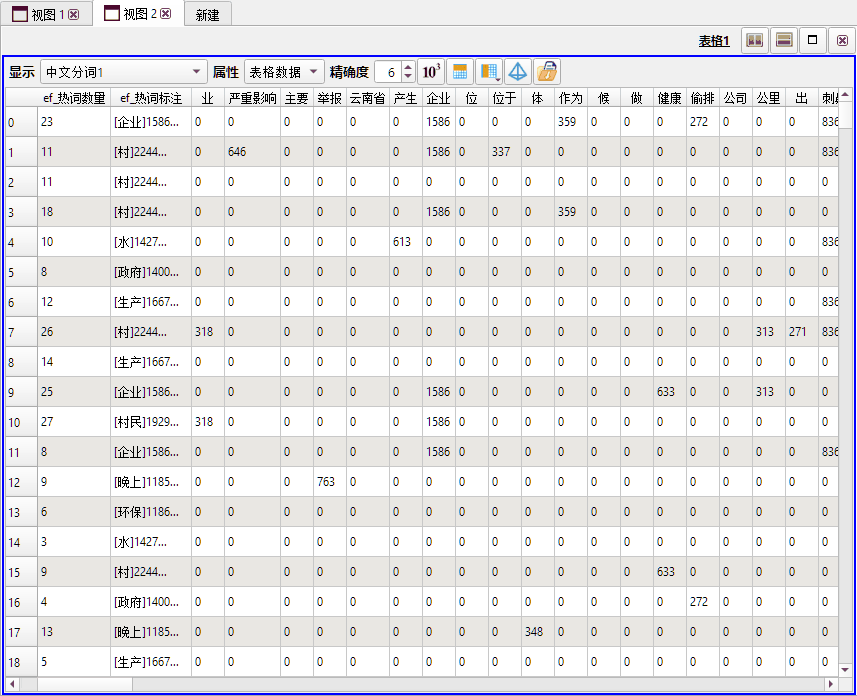
上图所示为使用本工具后,输出图层中所包含的关键词矩阵数据。除关键词矩阵之外,输出表格中还包含了原始文本、热词数量(本行文本包含了多少个热词)、热词标注(最大词频的热词)等注释性字段。
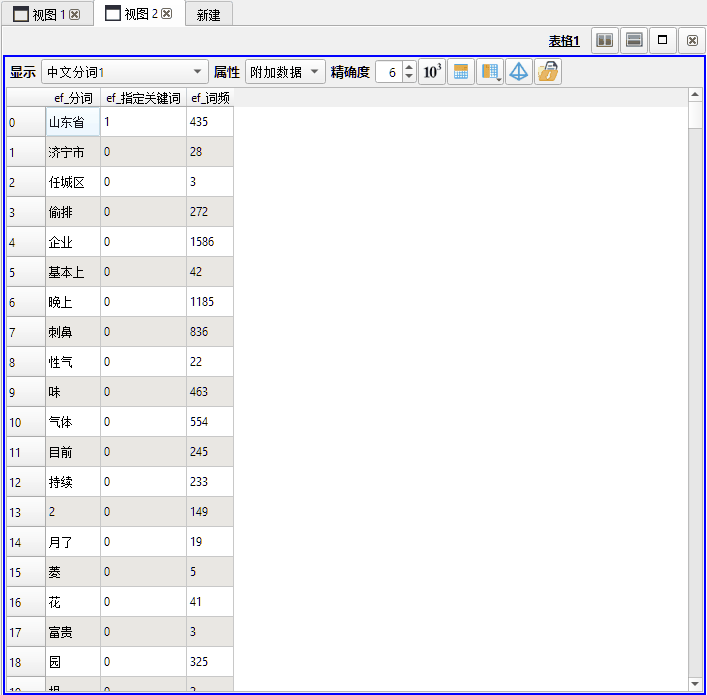
如上图所示,本次分词操作所产生的全部关键词(未作筛选操作),将保存在输出图层的附加数据中。